Research
Multilingual neural language models
I am deeply fascinated by multilingual neural language models (MNLMs): I believe they are compelling scientific objects from a cognitive science / linguistics perspective because they encode knowledge of different languages (often in the hundreds) in a shared set of parameters. They allow us to ask deep questions about what’s shared across languages at different levels of analysis (syntax, semantics, …). Unlike humans, MNLMs can be probed at scale, intervened on, and inspected at the unit level without measurement noise. This makes them powerful tools for testing language-general hypotheses about representation and processing. At the same time, they help counter the English-centric bias of both NLP and cognitive science. My work uses MNLMs to ask whether a shared representational space emerges across languages and whether such spaces explain human behavior and brain responses.
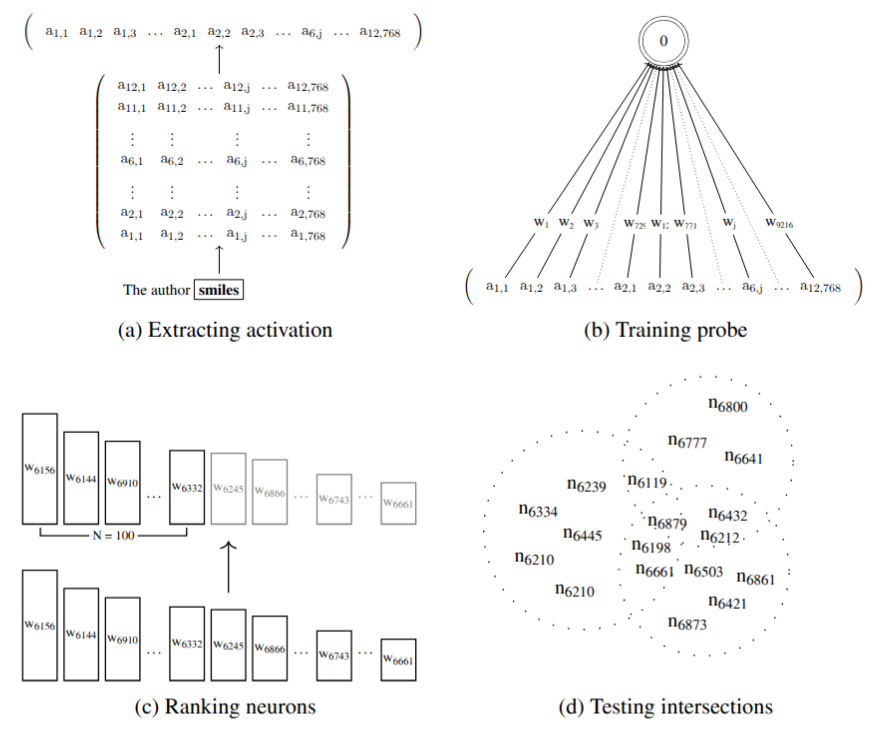
Interpretability of representations (syntax & semantics)
I analyze where and how MNLMs encode linguistic structure, testing whether the same latent dimensions support syntactic agreement and affective semantics across languages. I compare unit- and subspace-level analyses. Multiple studies point to the idea that these models represent the same linguistic phenomena in a consistent way across languages. (see Data-driven Cross-lingual Syntax: An Agreement Study with Massively Multilingual Models, Computational Linguistics, 2023 and The Emergence of Semantic Units in Massively Multilingual Models, LREC-COLING, 2024)
Reading across languages & probabilistic information
I relate model-based predictability (e.g., surprisal, cloze measures) to eye-tracking and reading behaviour across multiple languages. I am particularly interested in scaling effects (model size) and how they relate to different stages of processing (early/late fixation measures). I am also interested in the interplay between memory limitations and predictability, and which architectural biases that better capture human RTs. (see The Effects of Surprisal Across Languages: Results from Native and Non-native Reading, Findings of ACL AACL-IJCNLP, 2022 and Scaling in Cognitive Modelling: A Multilingual Approach to Human Reading Times, ACL Short Papers, 2023)
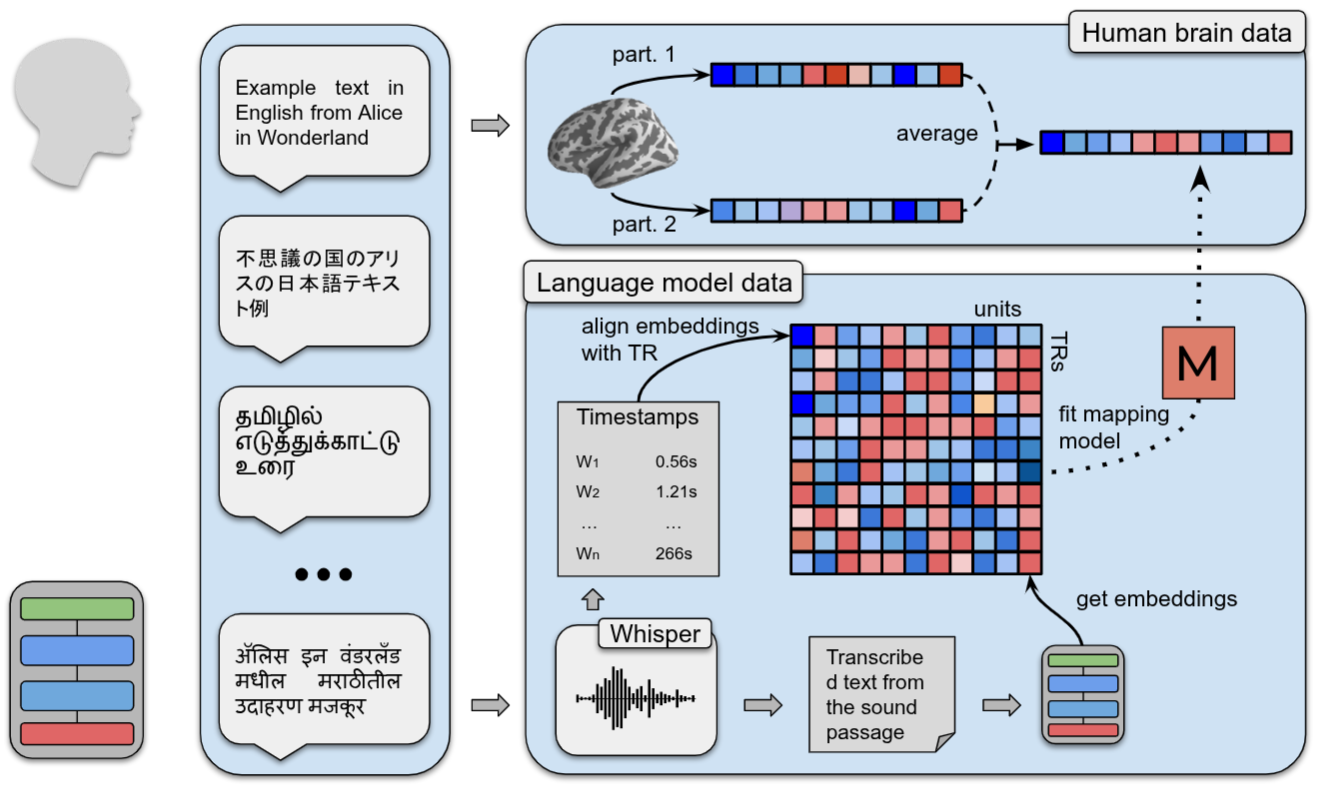
Brain–model alignment across languages
I train encoding models to predict fMRI responses to language from MNLM embeddings and test zero-shot transfer across languages and families. Results point to language-general principles in neural responses to linguistic input. (see Multilingual Computational Models Reveal Shared Brain Responses to 21 Languages, bioRxiv, 2025)
Non-arbitrariness and iconicity
Language is not fully arbitrary. My work examines systematic sound–meaning links using computational tools, behavioral data, and cross-lingual evaluation.
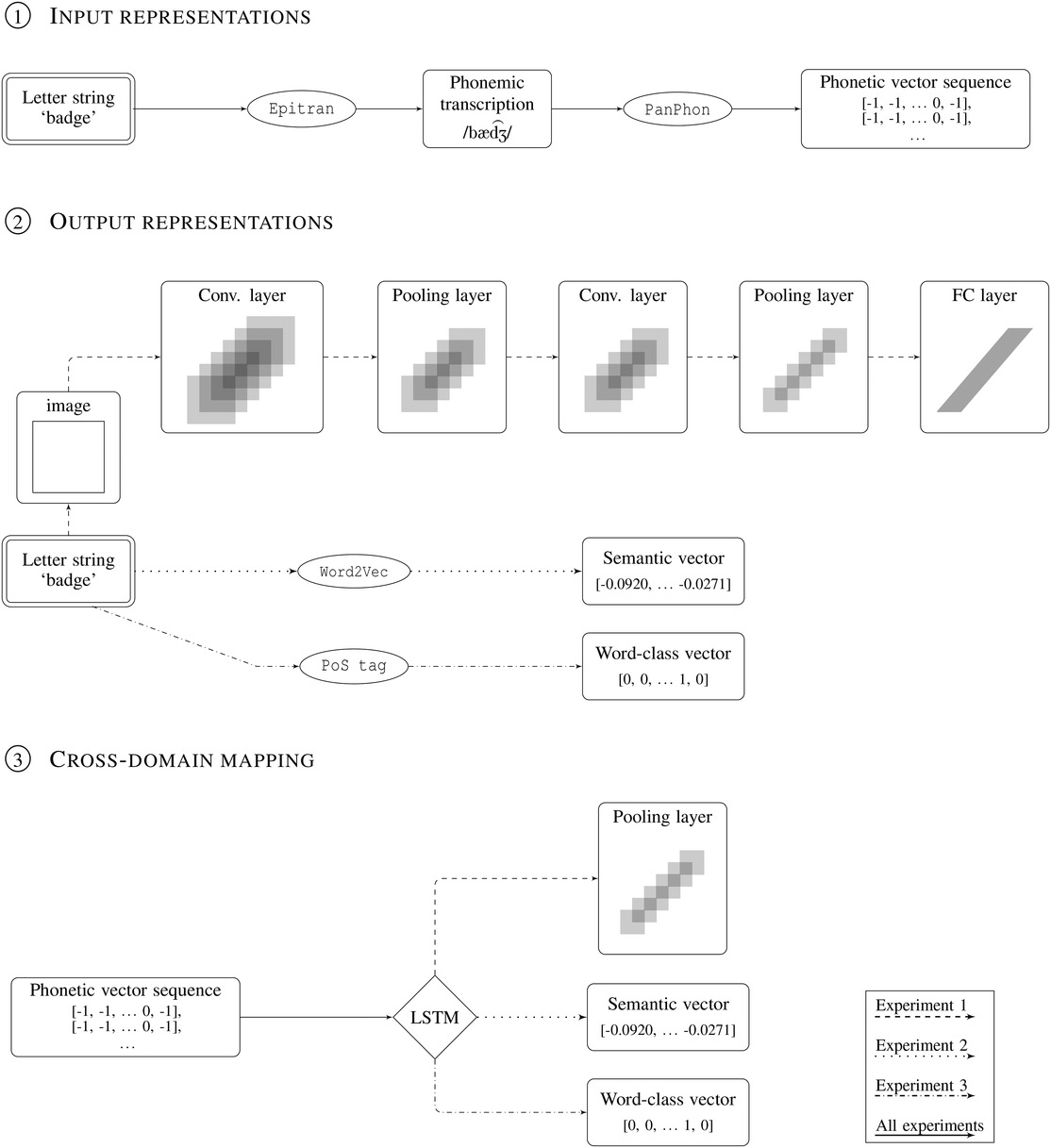
Cross-lingual phonosemantic correspondences
We train sequence models to map phonetic representations to sensory, semantic, and word-class targets across typologically distant languages, and test zero-shot transfer (so that the models are trained to map sound onto meaning representations in, say, English, and then tested in Tamil). Successful transfer indicates language-invariant cues linking form to meaning and syntactic class. (see A Cross-Modal and Cross-lingual Study of Iconicity in Language: Insights From Deep Learning, Cognitive Science, 2022)
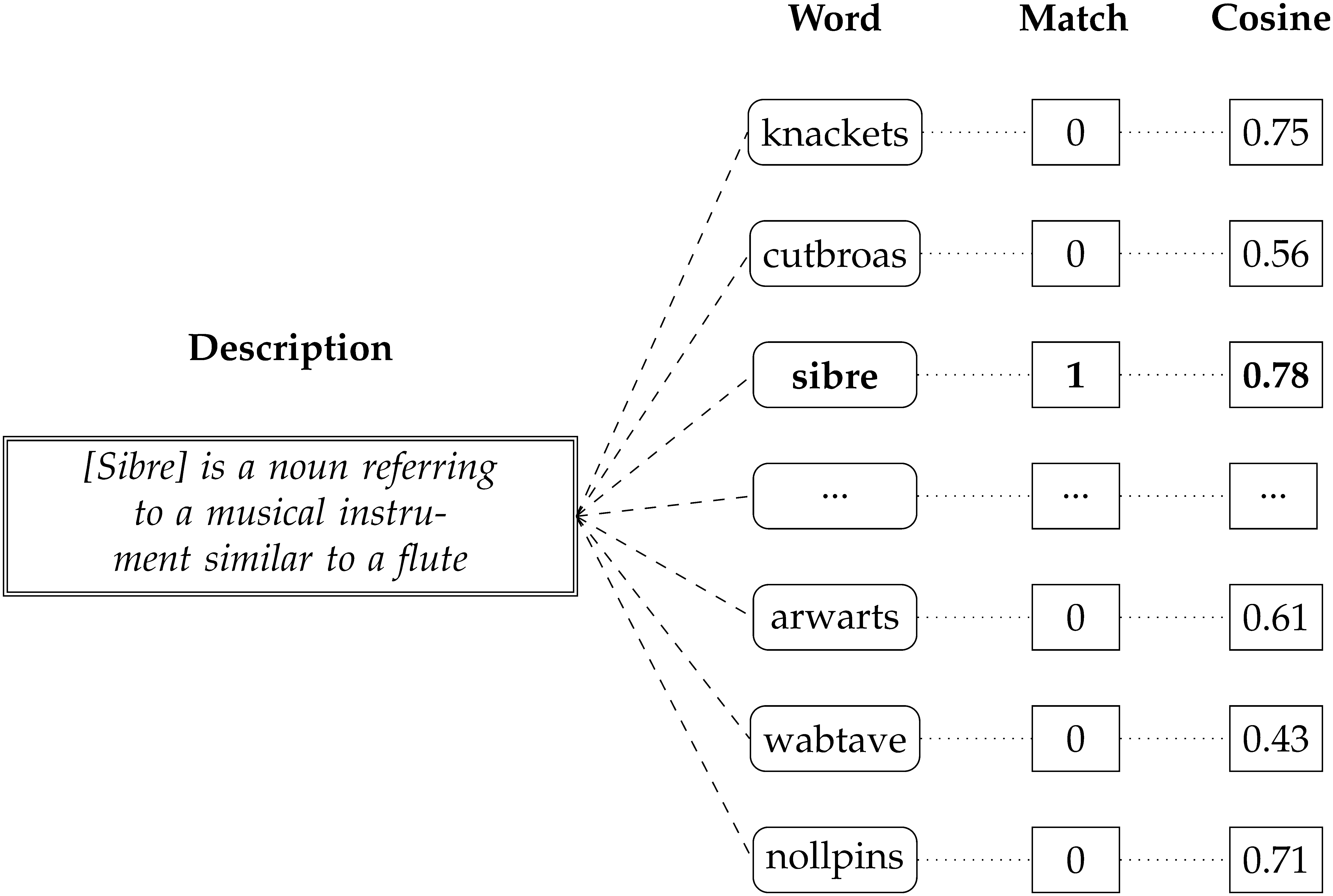
Meaning beyond lexicality (pseudowords)
Using exploratory–confirmatory designs, we test whether people (and language models) can ascribe declarative meanings to novel word forms. Human definitions and model outputs show systematic form-to-meaning mappings, supporting flexible generalization beyond the existing lexicon. (see Meaning Beyond Lexicality: Capturing Pseudoword Definitions with Language Models, Computational Linguistics, 2024)
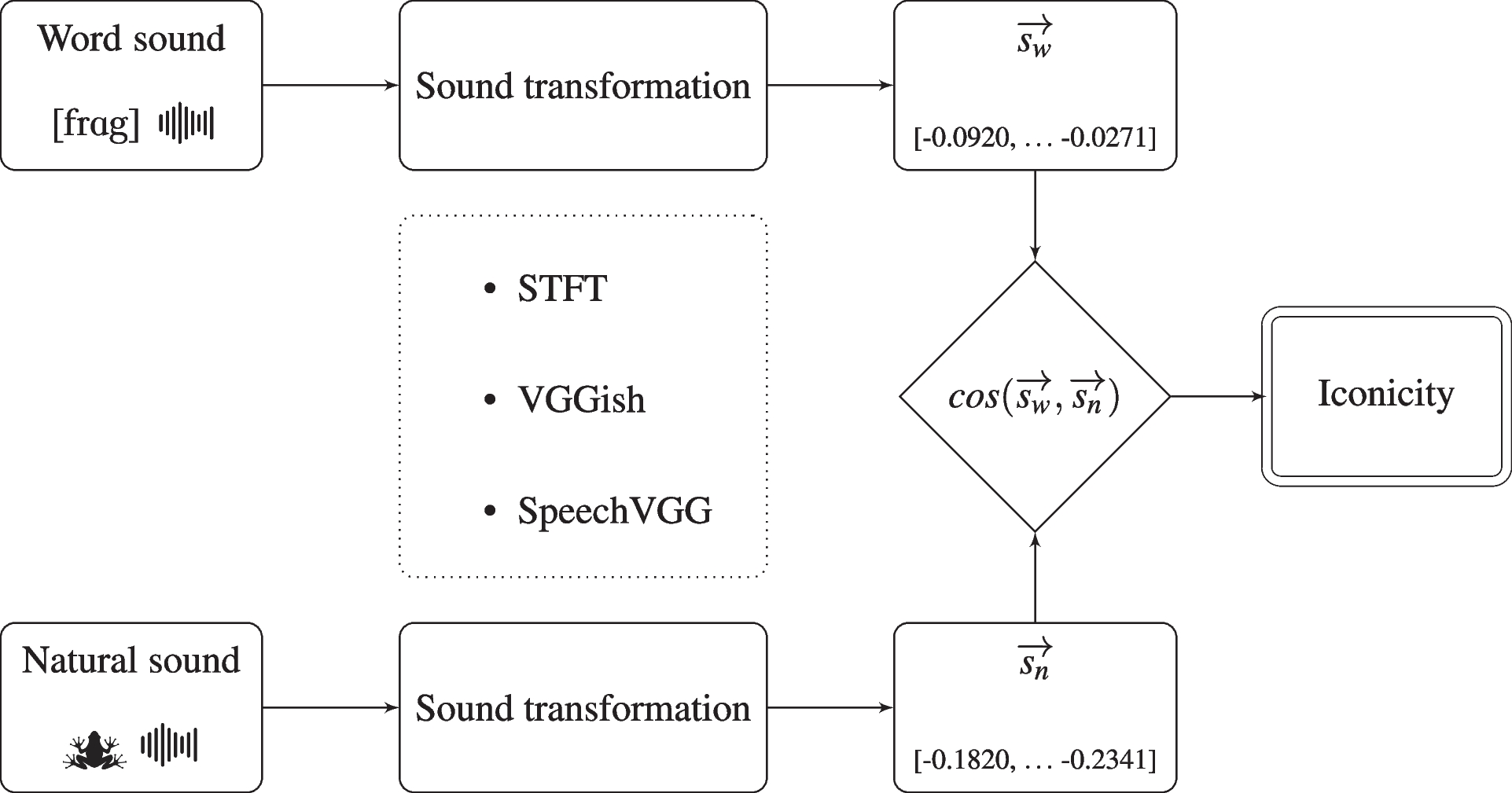
Auditory iconicity at scale
We embed natural sounds and spoken words into a shared auditory space (STFT, CNNs for sound and speech classification) to quantify direct resemblance between word sounds (e.g., the sound of the word "frog") and natural sounds (e.g., the sound of a frog croaking). Auditory imitation is widespread across the English auditory vocabulary, and aligns with human iconicity judgments. (see Cracking Arbitrariness: A Data-driven Study of Auditory Iconicity in Spoken English, Psychonomic Bulletin & Review, 2025)
Miscellaneous

Grounding concepts in spatial organization
We introduce SemanticScape, a distributional model of concepts grounded in the spatial relations between objects in natural images. The model learns from object–object distances to capture semantic similarity, relatedness, and analogical structure, complementing text- and vision-based embeddings. (see A Distributional Model of Concepts Grounded in the Spatial Organization of Objects, Journal of Memory and Language, 2025)

The cognitive cost of reasoning
We compare humans and large reasoning models across arithmetic, logic, and relational reasoning. The number of chain-of-thought steps generated by the model predicts human reaction times, both within and across tasks. This alignment shows that reasoning models mirror human cognitive effort. (see The Cost of Thinking is Similar Between Large Reasoning Models and Humans, OSF Preprint, 2025)
For full citations and links to journals and PDFs, see the Publications page.